![[Kubernetes] #2 Kubernetes Architecture](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcjchF6%2FbtrNmzhMTH4%2FPwwQhDWKuhDEqqUmaFuLPk%2Fimg.png)
CKA 자격증 준비 과정에서 Udemy의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의를 수강하고 정리한 내용입니다. 대부분의 자료는 해당 강의의 자료이며, 이외 레퍼런스는 관련 내용 상단에 표기하였으니 참고 바랍니다.
1. Cluster Architecture
쿠버네티스는 컨테이너선과 이를 통제하는 컨트롤 타워로 구성된 선단에 비유할 수 있는데요,
실제 컨테이너(애플리케이션)이 올라가는 Worker Node와 주요 구성 요소를 배포하고 제어하는 역할을 하는 컨트롤 플레인(Control Plane)이 포함된 Master Node로 구성되어 있습니다.

Master Node의 컨트롤 플레인은 현재의 상태(current state)를 사용자가 원하는 상태(the desired state)로 끊임없이 조정해주는 컨트롤 타워로 보면 됩니다.
따라서 Master Node에는 실제 서비스와는 관련 없는 쿠버네티스의 운영과 관련된 컴포넌트들이 존재하며,
Workker Node에는 컨테이너를 관리하고 Master Node와 통신하기 위한 컴포넌트들이 존재합니다.

각각의 컴포넌트들이 어떠한 역할을 하는지 좀 더 살펴보겠습니다.
2. ETCD
2.1. ETCD란?
ETCD : distributed, reliable, key-value store
ETCD는 key, value 형태의 데이터를 저장하는 분산형 스토리지입니다.
ETCD는 서버가 다운되어도 잘 작동할 수 있도록 Replicated state machine(RSM)라는 방법을 사용하고 있습니다.
<ETCD에 대한 더 자세한 내용은 카카오 테크 블로그(https://tech.kakao.com/2021/12/20/kubernetes-etcd/) 참고>
2.2. ETCD in Kubernetes
ETCD는 쿠버네티스 클러스터의 모든 정보를 저장하는 용도로 사용되며, kube-api server와만 통신합니다.
(e.g. 클러스터에 어떤 노드가 몇 개 있고, 어떤 파드가 어떤 노드에서 동작하고 있는지)
아래와 같은 모든 클러스터의 정보를 담고 있으며, Node가 추가되거나 정보가 업데이트되면 ETCD 서버에 반영됩니다.
- Nodes
- PODs
- Configs
- Secrets
- Accounts
- Roles
- Bindings
- Others
클러스터를 어떻게 구성하냐에 따라 ETCD는 다르게 배포됩니다.
두 가지 방법이 주로 사용되는데,
- scratch
- ETCD를 마스터노드에서 바이너리 파일로 직접 설치해야 함
- IP나 TLS 등의 다양한 설정을 고려해야 하므로 비교적 복잡하다.
- kubeadm tool
- etcdctl을 이용해서 kube-system 네임스페이스에 Pod로 설치하는 방식
고가용성(HA, High Availability) 클러스터에서는 Master Node가 여러 개일 수 있습니다.
그런 경우 ETCD는 각 마스터노드에 배포가 되어야 하며, ETCD의 설정을 잘 고려해서 설정해야 합니다.
따라서 Master Node가 여러 개일 경우에는 kubeadm tool을 이용하는 것이 더 적합할 수 있다고 합니다.
고가용성 : 가용성이란 시스템 고장 발생 시 얼마나 빠른 시간 내에 치료가 되어 다시 정상적으로 서비스할 수 있는 상태인지를 분석하는 척도. HA 구성은 장애극복 처리에 중점을 두고, 이중화와 같은 작업을 하는 것을 의미한다.
2.3. ETCDCTL
ETCDCTL은 ETCD 서버와 상호작용하기 위한 CLI 툴입니다.
2가지의 API 버전(Version 2, 3)이 있으며, default 설정은 Version 2를 사용합니다.
# etcdctl API를 버전 3으로 사용하기 위한 설정
export ETCDCTL_API=3
# 버전 확인
etcdctl version
# Write
etcdctl put foo bar
# Read
etcdctl get foo3. Kube-api server
쿠버네티스의 모든 명령과 통신은 API를 통해서 이루어지며, 그 역할을 담당하는 것이 kube-api server입니다.
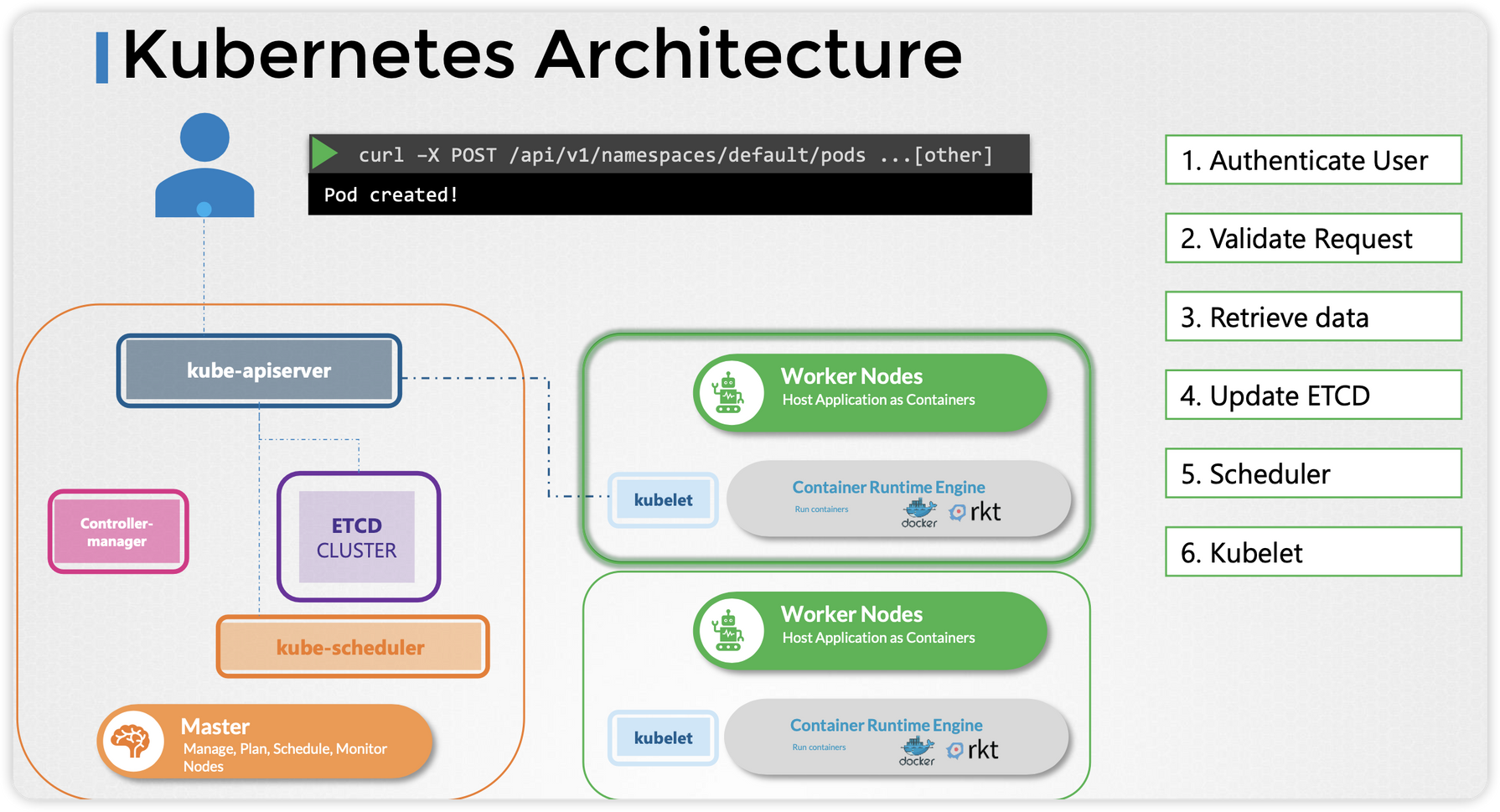
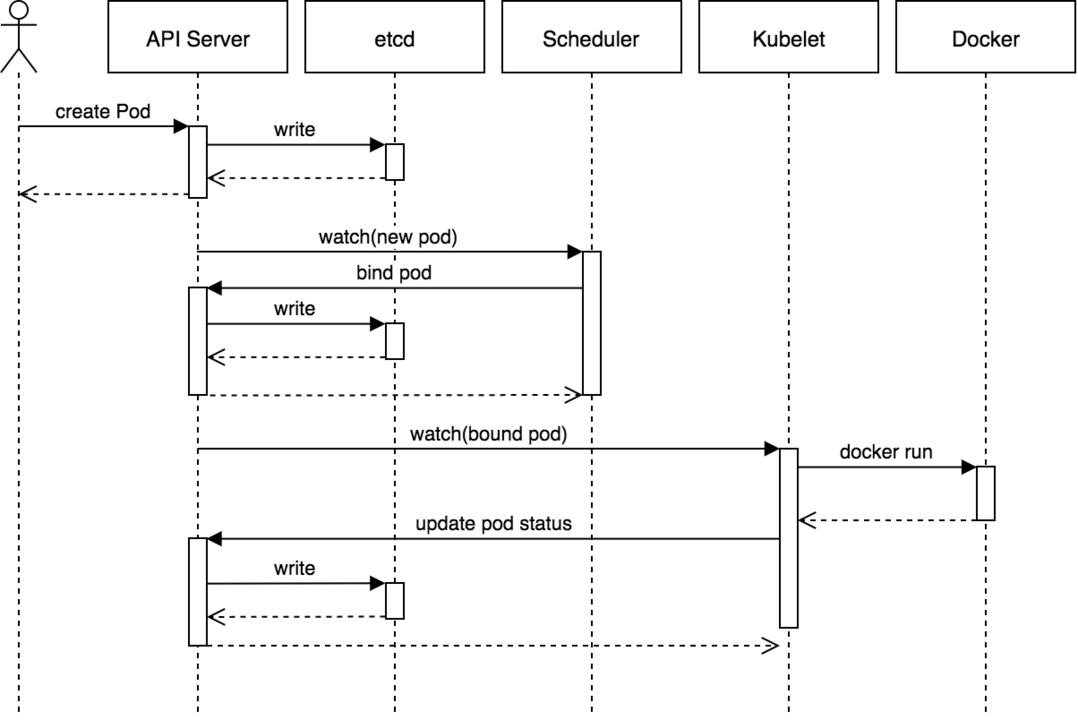
유저가 kubectl 명령을 실행하면, 백단에서는 kube-api server로 REST API 요청을 보냅니다.
1) kube-api server는 유저를 인증하고,
2) 요청의 유효성을 검사한 뒤,
3) ETCD에 데이터를 검색하고 검색된 정보를 응답 보내게 됩니다.
4) (Pod 등의 오브젝트를 생성하는 명령이라면) ETCD에 내용을 업데이트하고,
5) 스케쥴러는 api-server를 모니터링하고 있다가 노드에 할당되지 않은 새로운 Pod가 있다면 kube-api server에게 알려주며, api-server는 ETCD의 정보를 업데이트한 뒤 적합한 워커 노드의 kubelet에게 일을 시킵니다.
6) kubelet은 노드에 Pod를 생성하고, kubelet이 api-server에 상태를 알려주면 api-server는 ETCD 클러스터에 정보를 업데이트합니다.
4. Kube Controller Manager
https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
kube-controller-manager
Synopsis The Kubernetes controller manager is a daemon that embeds the core control loops shipped with Kubernetes. In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system. In Kubernetes, a
kubernetes.io
kube controller manager는 쿠버네티스의 다양한 컨트롤러를 관리하는 패키징된 클러스터입니다.
각 컨트롤러는 관련 리소스들을 모니터링하며 원하는 형태(the desired state)로 동작하도록 관리합니다.
<e.g. 다운된 노드가 없는지(Node-Controller), 파드가 의도된 복제 숫자를 유지하고 있는지(Replicaset-Controller) 등>
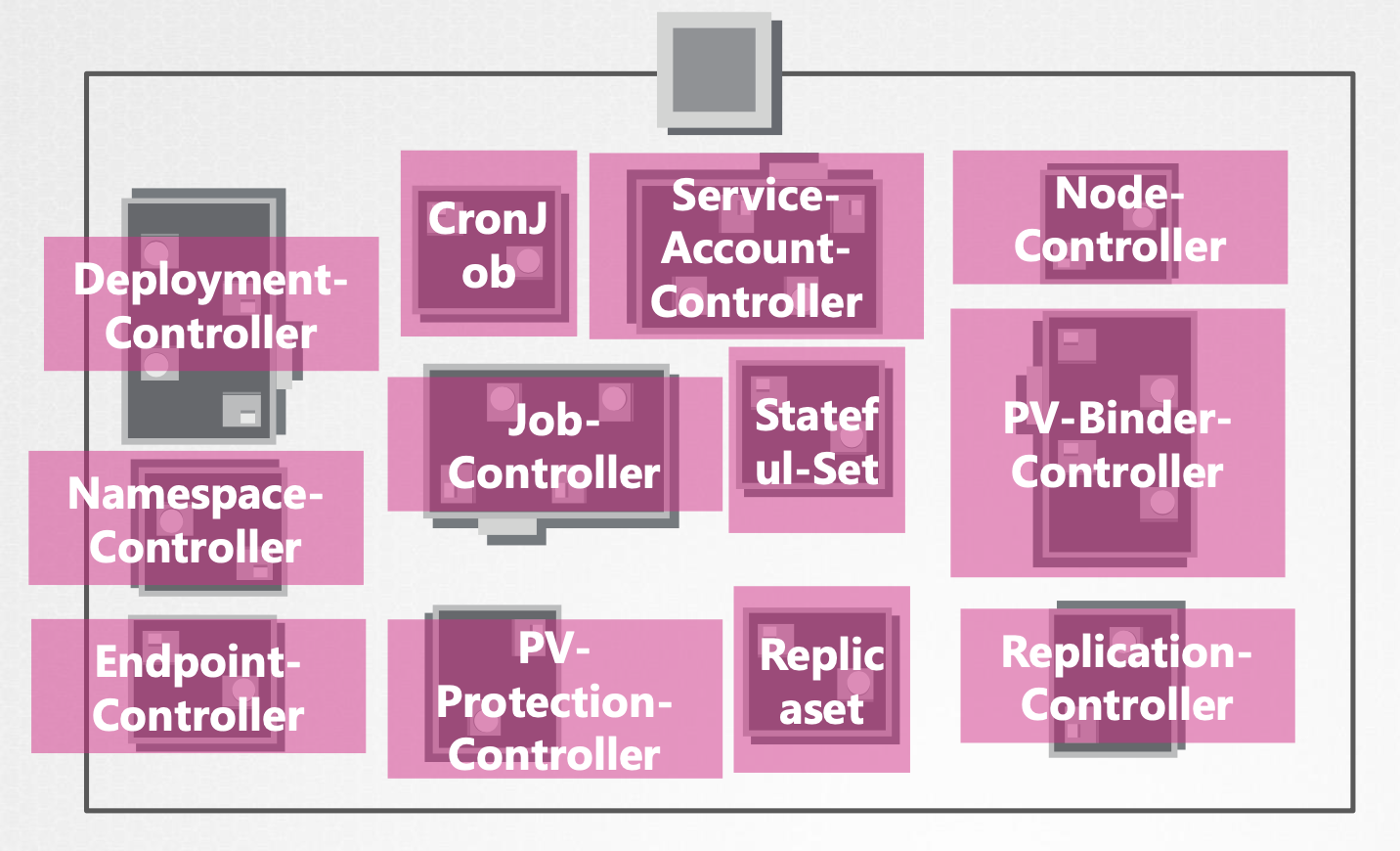
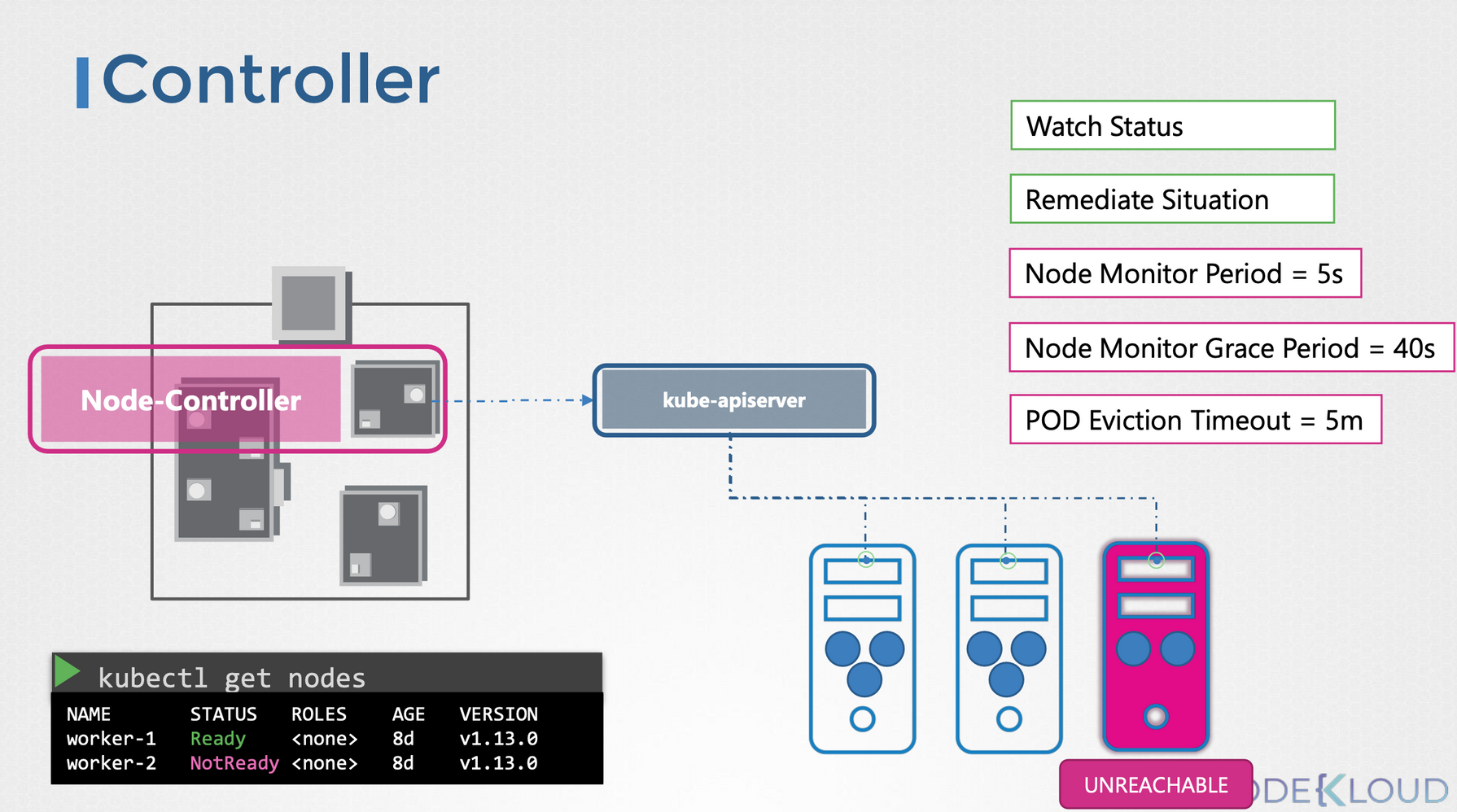
각 컨트롤러의 역할은 Watch Status와 Remediate Situation으로 나뉩니다.
Node Controller를 살펴보자면,
1) Watch Status
- 노드의 상태를 5초마다 확인한다.
2) Remediate Situation
- 노드가 40초 동안 응답이 없으면 unreachable로 마킹
- unreachable이 된 후 5분 동안 복구를 기다려도 응답이 없으면 할당된 Pod를 모두 제거
5. Kube Scheduler
https://www.linkedin.com/pulse/kubernetes-custom-scheduler-python-vivek-grover/
Kubernetes Custom Scheduler in Python
Kubernetes is a popular open source platform for container orchestration. It is highly configurable, extensible and designed to be automated by writing client programs.
www.linkedin.com
어떤 Pod가 어떤 Node에 배포되어야 하는지를 여러 기준들(resource requirements, label, etc)에 따라 결정하는 역할을 합니다.
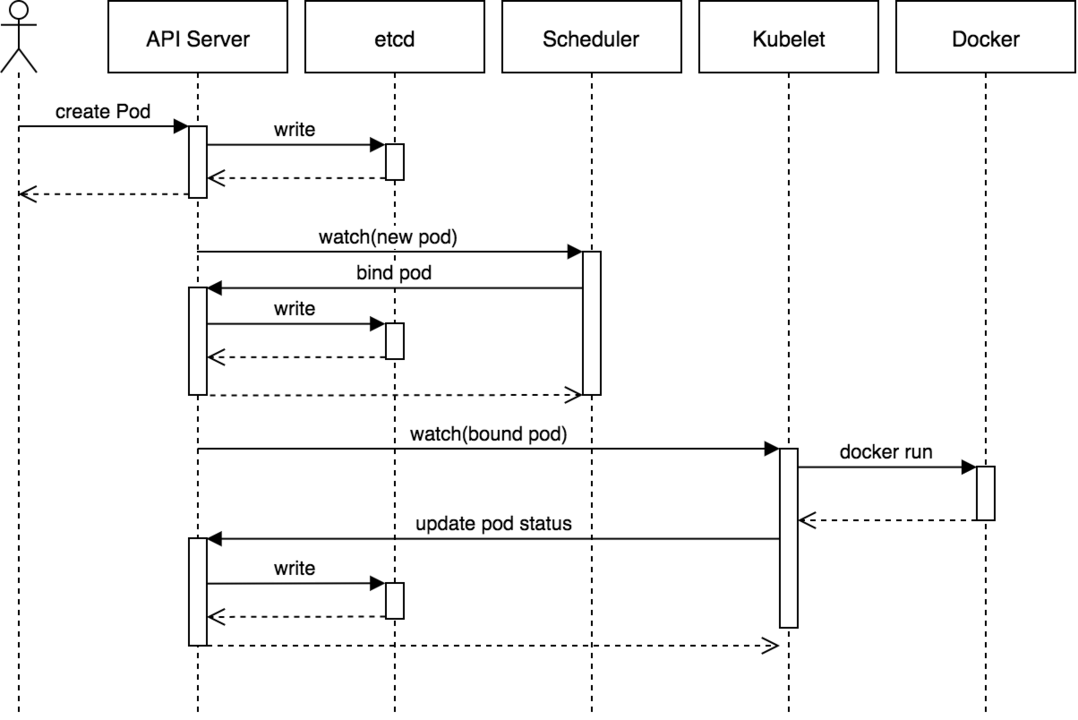
kube-api server에서 설명한 것과 같이, scheduler는 api server를 지켜보고 있다가 Node가 할당되지 않은 Pod가 있으면 적절한 Node에 Pod를 할당합니다.
scheduler는 어떻게 적절한 Node를 선택할까요?
간단하게 보자면 아래와 같습니다.
[Scheduling Process]
- Filter Nodes
- 제약사항들을 충족하는 노드들만 남긴다. (스토리지, 가용 리소스, 라벨, 포트, 노드 컨디션 등을 다양하게 고려)
- Rank Nodes
- 필터링되고 남은 노드 중 가장 자원이 많이 남는 등의 조건에 따라 노드의 순위를 매기고, 최적의 노드에 Pod를 할당한다.
6. Kubelet
Worker Node가 배라면, Kubelet은 배의 선장과 같은 역할을 맡습니다.
Kubelet은 모든 Worker Node에 배포되어 kube-scheduler가 Pod를 특정 Worker Node에 할당하면, 해당 Worker Node의 kubelet은 Pod를 생성하고, 관리하고, 삭제하는 역할을 수행합니다.
kubelet은 크게 3가지 역할을 수행합니다.
- Register Node
- kube-api server에 워커 노드를 자체 등록(self-registration)한다.
- Create PODs
- Scheduler로부터 해당 노드에 Pod를 생성하라는 요청이 오면, Container Runtime에게 컨테이너 생성을 요청한다.
- Monitor Node & PODs
- 모든 kubelet에는 컨테이너의 리소스 사용량이나 퍼포먼스를 측정할 수 있는 cAdvisor(Container Advisor)가 탑재되어 있음.
- kubelet의 cAdvisor는 해당 Node에서 실행되고 있는 모든 컨테이너의 CPU, Memory, File, Network 사용량 등을 모니터링하고 분석한다.
7. Kube proxy
https://coffeewhale.com/k8s/network/2019/05/11/k8s-network-02/
[번역] 쿠버네티스 네트워킹 이해하기#2: Services
쿠버네티스 네트워킹 이해하기 시리즈 중 첫번째 포스트에서는 쿠버네티스가 가상 네트워크 device와 라우팅 규칙을 이용하여 한 Pod가 다른 Pod와 어떻게 통신하는지 알아봤습니다. 이번 글에서
coffeewhale.com
https://velog.io/@squarebird/Worker-Node-Kube-Proxy
[Worker Node] Kube-Proxy
Kubernetes의 Network을 책임져주는 Kube-Proxy에 대해 알아보자
velog.io
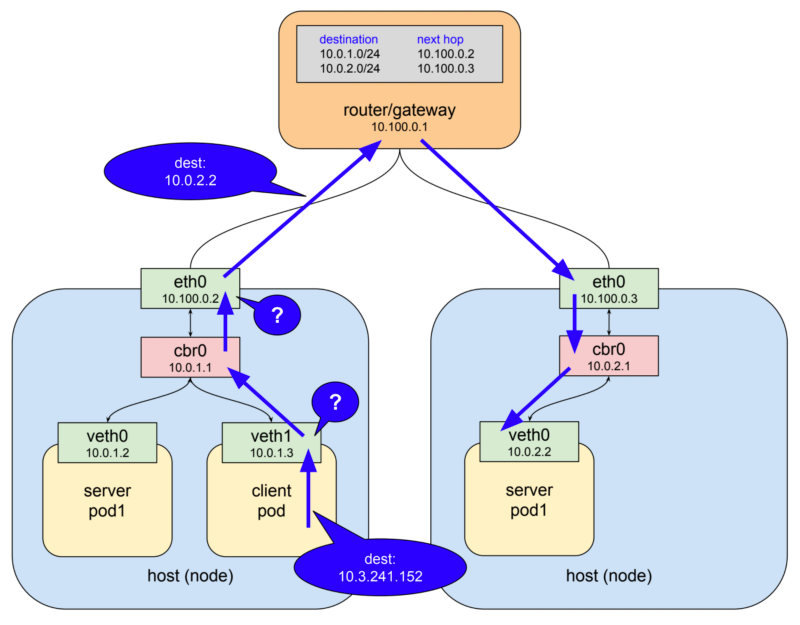
Kube-proxy는 모든 Worker Node에 설치되어, 클러스터 내의 모든 Pod가 서로 통신할 수 있도록 도와주는 역할을 합니다.
Worker Node에 Pod를 구성할 경우, 두 가지 Interface를 가지고 있습니다.
하나는 Worker Node의 Host interface(eth0)이고, 하나는 Pod interface(veth0, veth1)입니다.
여기서 Kubernetes에서 Pod들 사이의 통신에서 Host interface와 Pod interface를 사용하면 정상적으로 통신이 될까요?
물론 IP를 이용해서 통신은 가능합니다.
하지만 문제가 생겼을 때 Node나 Pod를 파괴하고 재생성하는 것이 핵심인 Kubernetes에서, 장애가 발생하여 Node나 Pod가 교체되었을 때 해당 IP가 유지될 것이라는 보장이 없습니다.
그렇기 때문에 이후에 배울 Service라는 오브젝트를 통해 DNS Name으로 접근하고, kube-proxy는 Pod나 Node가 추가되거나 변경될 때마다 DNS Name에 접근할 수 있는 Rule을 추가하여 주는 방식으로 Pod가 서로 통신할 수 있도록 합니다.
8. 그래서 Kubernetes가 왜 표준이 됐나요?
https://coffeewhale.com/k8s-isnt-containers
[번역]쿠버네티스는 단순히 컨테이너를 관리하는 툴이 아닙니다.
나름 조회수가 잘 나왔던 저의 블로그 글 중 하나인 쿠버네티스 API서버는 정말 그냥 API서버라구욧에서 쿠버네티스 API 서버가 일반적인 API 서버와 크게 다르지 않다는 점을 강조한 내용으로 글
coffeewhale.com
모든 컴퓨터의 리소스를 오브젝트로 표현할 수 있으며, 쿠버네티스 API로 제공하고 있기 때문이라고 합니다.
자세한 내용은 위 블로그를 참고하시면 좋을 듯 합니다.
'스터디 > DevOps' 카테고리의 다른 글
| [Kubernetes] #4 ReplicaSet (0) | 2022.10.29 |
|---|---|
| [Kubernetes] #3 Pod (2) | 2022.10.08 |
| [Kubernetes] #1 Kubernetes(쿠버네티스) 개요 및 가상화 기술 (0) | 2022.09.29 |
| [Kubernetes] 쿠버네티스(Kubernetes)에서 주피터허브(JupyterHub)에 Random Port 설정하기 (0) | 2022.04.17 |
| [Kubernetes] 쿠버네티스(Kubernetes)에서 주피터허브(JupyterHub) 구성하기 (2) | 2022.04.17 |