![[검색엔진] Elasticsearch 랭킹 (2) - 유사도 점수 정규화](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcMRBfS%2FbtsGgbstEKm%2FcHj1lvJTYCSJMNPbN2xBHk%2Fimg.png)
개요
Elasticsearch에서 질의어를 기준으로 유사도를 매기는 BM25 점수는 0~무한대의 값을 가진다. (물론 현실적으로는 대체로 20, 최대 100 이내의 점수일 것이다)
검색에서 유사도 점수만 사용하는 경우도 있지만, 다른 점수(문서 자체의 품질 점수, 또는 특정 필드의 가중치 점수 등)를 같이 활용하여 랭킹에 사용하기도 한다.
유사도 점수를 다른 점수와 결합하여 사용하기 위해서는 그 자체로 사용할 때 몇 가지 단점이 있다.
- BM25 점수가 3, 15일 때의 동일한 품질점수 0.5는 영향력 차이가 매우 크다.
- BM25 점수가 어느 정도의 값을 가질지는 질의어에 따라 상당한 차이가 발생하기 때문에 품질점수의 영향력을 예측하기가 매우 어려워진다.
물론, 검색된 문서들간의 상대적인 비교가 목적이기 때문에 정규화(또는 스케일링)가 반드시 필요한 것은 아니지만, 여기서는 어떤 방법이 있는지를 정리해본다.
유사도 점수를 0~1로 나오게 하기 위해서는 BM25 수식을 수정하는 방법, IDF 값을 정규화하는 방법, BM25가 아닌 다른 유사도 기법을 사용하는 방법 등이 있겠지만, 여기서는 BM25 점수 자체를 0~1 사이로 변환하는 방법에 대해서만 알아본다.
점수 변환 방법과 그래프 분포
리서치를 했을 때 유사도 점수를 정규화하는 방법이 흔히 사용되지 않는 것 같기도 하다.
그와 관련된 논의나 논문이 많지는 않으며, 대부분은 최근 벡터 유사도를 활용한 시멘틱 서치와의 결합 방법인 RRF, CC와 관련된 논의 위주인 것으로 보인다. (참고로 RRF에서 주로 사용하는 방법은 Min-Max Scaling인 듯하다)
Min-Max Scaling
value_new = ( value - min(value) ) / ( max(value) - min(value) )- 데이터의 분포는 변하지 않고, 0~1 사이로 값을 변환하기 위한 기법
- 가장 베스트이지만.. min,max의 통계값을 사용해야 하기 때문에 ES 스크립트에서 구현할 수 없다.
Saturation
value_new = value / ( k + value )
* k가 커질수록 기울기가 완만해진다.- 계 없이 값을 0~1 사이로 변환할 수 있는 방법 (Sigmoid에서 각 값의 제곱이 사라진 버전)
- 값이 증가함에 따라 점수가 증가하지만, 일정 수준 이상에서는 점수 증가가 포화(Saturate)되어 더 이상 크게 증가하지 않는 방
- BM25의 변형된 TF식의 k 값도 일종의 saturation function
- 단순하기에 계산 성능에서 이점이 있지만, 원래 점수의 분포가 달라진다는 단점이 있다.

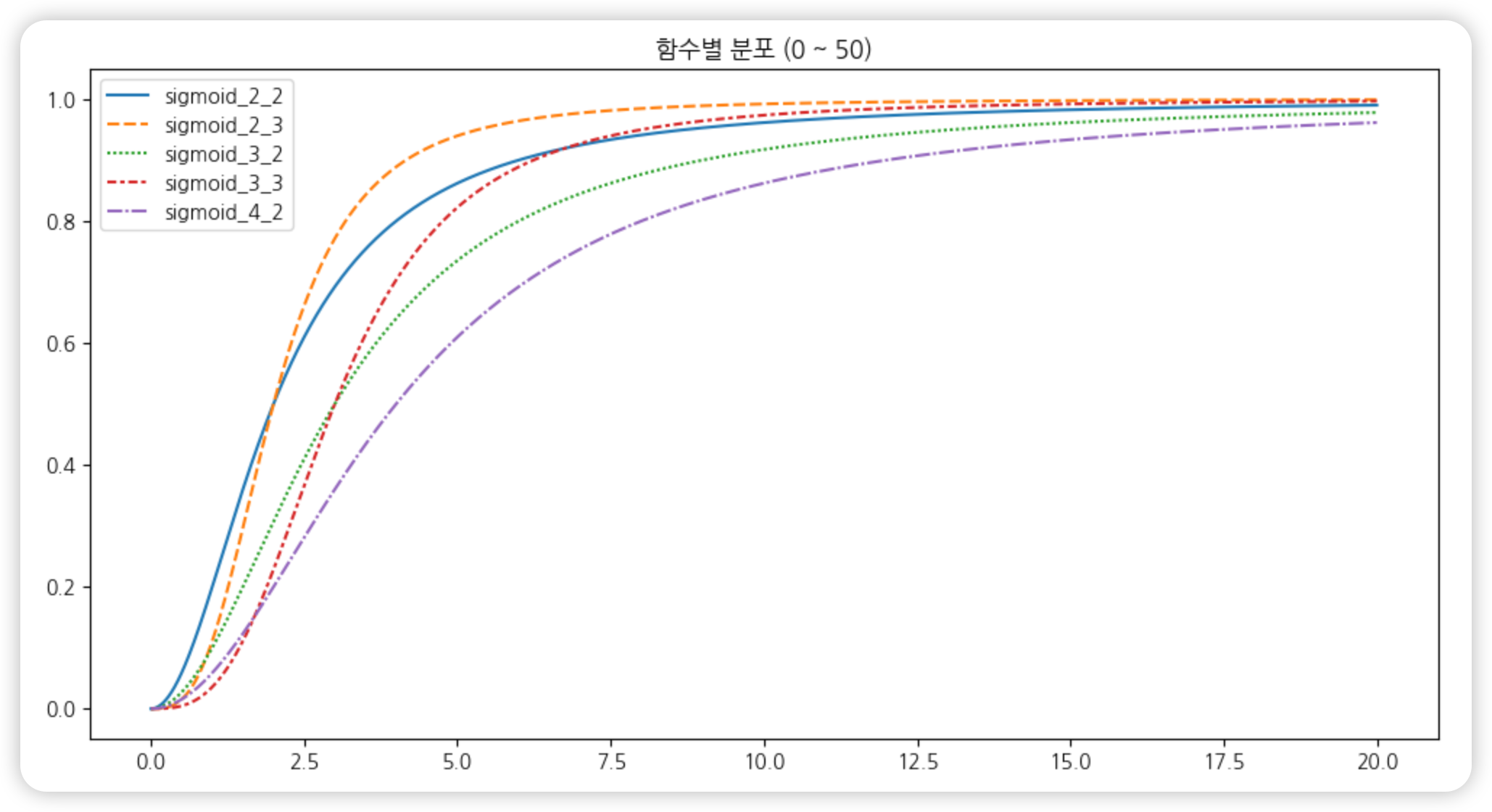
Sigmoid
value_new = value^a / ( k^a + value^a )
* k가 커질수록 기울기가 완만해진다.
* a가 커질수록 초기의 증가가 느려지고, 일정 구간 이후 증가가 빨라진다.- Saturation과 유사하게 포화되는 그래프를 가지지만, a값의 조정으로 초기/후기의 증가 기울기를 조정할 수 있다.
- 포화에 대한 개념은 동일하되 제곱의 사용으로 성능상 약점이 있기 때문에, 특정한 목적이 아니라면 Saturation 사용으로 충분할 듯하다.
Max
value_new = MIN(value, k) / k- Min Max Scaling과 유사하지만, 통계 정보를 알 수 없기 때문에 점수의 상한선을 임의로 두는 방식이다.
- MAX값을 너무 높게 잡으면 유사도의 영향력이 줄어드는 문제가, 너무 낮게 잡으면 일정 이상의 점수는 모두 동일한 유사도를 가지는 문제가 발생한다.

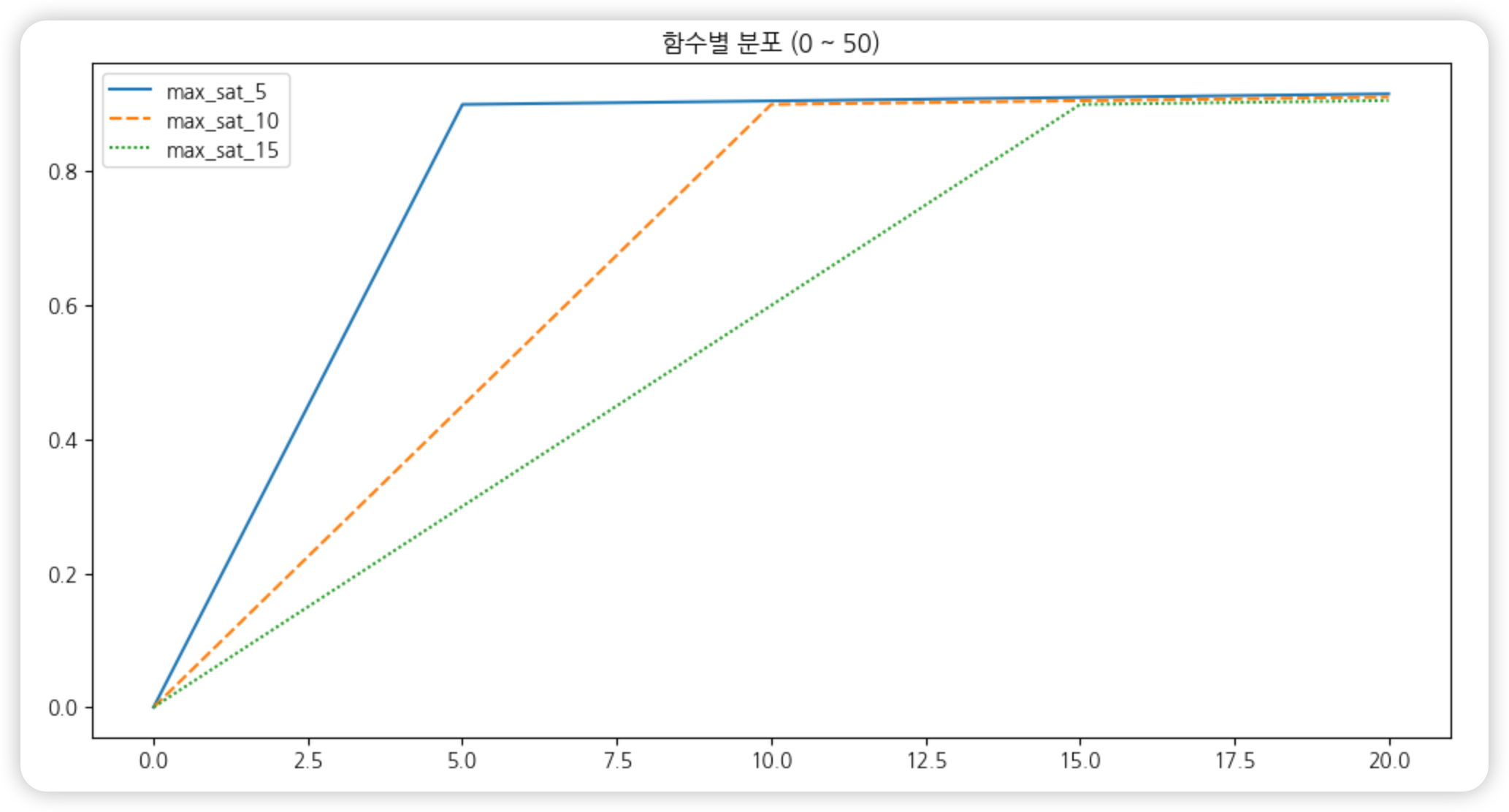
Max Step (가칭)
value_new = ( MIN(value, k1) / k1 ) * w1 + (( MIN(value, k2) - MIN(value, k1) ) / (k2-k1) ) * w2- (실제 주로 활용되는 방법은 아닌 듯하다. 그냥 내 생각대로 구현해본 방법)
- Max에서 k 이상의 점수가 모두 동일한 유사도를 가지는 문제를 해결하기 위해, 두 구간으로 나눠 포화 개념을 추가한 버전.
- 0~k1까지 빠르게 증가하고, k1~k2까지는 천천히 증가하도록 설정하는 방식 (아래 그래프는 일괄적으로 k2=100, w1=0.9, w2=0.1을 적용)
결론
회사 내 데이터를 활용하여 실제 BM25 분포를 살펴보기도 했었다.
사용자가 주로 사용하는 쿼리 상위 1,000개를 활용하여 살펴보았고, 쿼리별 BM25의 평균과 최대값을 각각의 기법으로 변환했을 때의 분포를 살펴보고 어떤 방법이 적절할지를 고민해봤다.
다만 이는 회사 내의 데이터가 포함되어 있기에 상세히 기재하지는 않았다.
짧게만 적어보자면 원본 BM25 점수는 대부분 쿼리별 평균 10 이하의 점수였고 최대 30 이하의 점수 분포를 가졌다.
20 이상의 점수가 나오는 쿼리와 결과를 살펴봤을 때 그 점수가 충분히 의미가 있지는 않다고 개인적으로 판단했고,
결론적으로는 Max Step을 10, 20의 두 구간으로 나눠서 BM25 점수를 정규화하여 사용해보기로 했다.
(물론 랭킹의 결과가 좋지 않으면 수정될 수 있다)
'스터디 > 검색 엔진' 카테고리의 다른 글
| [검색엔진] Elasticsearch - 인덱스 교체 전략 (2) | 2024.04.14 |
|---|---|
| [검색엔진] 검색 엔진 리서치 (1) | 2024.01.21 |